In my previous post in this series, I discussed about high level requirements of the client and technology stack that we choose to provide the solution as well as the primary data structure and a bit about the data flow design. If you haven't red, I highly recommend you to read that to get the context of this article.
Redis DB as a primary Database
In order to understand how we arrived at consensus in terms of making a decision to choose redis as a primary database, there is a bit of history.
Our client basically had an existing desktop based system which was a .net win forms application using redis as a database. Honestly, this is the first time where I saw redis used as a primary database. I had mixed feeling seeing this. The design looked fascinating and scary at the same time.
The reason to worry is data persistence!
Redis is basically an in-memory data structure store. In layman terms, what it means is, if you write a piece of data to redis, it will be stored in RAM and not on disc. Hence its majorly used as a cache rather than database. Then I learned that there are configurations in redis using which you can choose to persist the data in disc. By default, it persists data to disc with snapshotting strategy. However, you can choose to persist using AOF strategy or both combined.
When I looked at the configuration of the existing system, it was configured to use snapshotting strategy with the configuration value save 20 1(i.e, take a snapshot every 20 seconds if there is at least 1 key change).
Still it was not convincing enough to use this as a primary data store, because if you go with above and your system happened to crash, in the worst case you would loose 20 seconds of data. And in sports, every second matters! specially when you are an official governing body of a specific sport (I cannot reveal the name here due to NDA constraints).
Unfortunately, it was not possible to speak to any of the technical people who developed this system. The system was however running successfully in production for couple of years.
Further digging of all the materials shared by client, I could figure out that there was multiple instance of redis which would run as a backup system and receive the data with pub-sub. With this you could achieve certain degree of data safety in terms of durability. If not perfect, may be its a good enough kind of safety for that occasional unfortunate failure scenario.
But as you guessed, the performance was blazingly fast!
Now this is a benchmark for our cloud based solution which had all the feature of the desktop + some feature enhancements + integrating with external systems with sub-second latency.
So I definitely didn't wanted to move away from Redis but also introduce further measures to ensure durability. After doing some research we arrived at following configuration -
- Kept the snapshotting configuration as is, which was with the value save 20 1 (i.e, take a snapshot every 20 seconds if there is at least 1 key change)
- Enabled AOF strategy with the value appendfsync everysec
- Enabled master-slave replication with asynchronous configuration
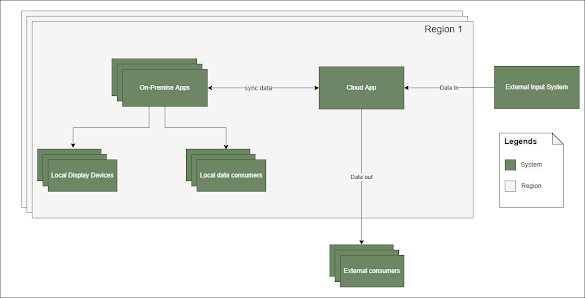
Why not redis in-built replication to sync data from On-Premise to Cloud and vice versa?
- In redis server, each database is just a logical separation.
- In our cloud redis server, each logical redis database holds the data of one specific tournament.
- The on-premise redis server holds the data of only 1 tournament which is running on that location.
- The on-premise and cloud runs in a toggling active-passive mode for a tournament. Meaning, at any given moment of time for a give tournament, the writes can either happen to cloud or on-premise but not to both.
- The entire setup runs in linux environment in a docker engine both on cloud and on-premise.

- The on-premise needs only 1 tournament data but cloud deals with multiple tournament data, each in its on logical db.
- Since there are multiple on-premise instances at various physical locations, each running a single tournament, there is no clear single node which we can consider as master node.
- Since everything runs inside a docker engine, there is additional overhead in the configurations in terms of network mapping.
- Cloud to on-premise: This is a straightforward download of data from cloud to on-premise for the specific tournament. The on-premise db will get overridden by the backup file.
- On-Premise to Cloud: Each on-premise redis transaction is delivered to cloud azure redis using azure webjob via Kafka. Basically, on-premise will push the transaction messages to Kafka, and azure web job in cloud has a logic to consume these messages from Kafka and commit it to redis db in the cloud.
Why Kafka?
- Azure Cosmos DB - This is a cloud only solution and that's the main reason to drop this for our application. Also, its more of a distributed storage system rather than a message streaming platform. Hence if we go with this, we needed additional other PAAS service or custom implementation to deliver the data to external systems.
- Azure Event Hub - This was one of the toughest decisions to make because both Kafka and Event Hub had almost equal capabilities. Compared to Kafka, Event Hub was fairly new to the market. Kafka is already a matured framework with wide community support and our client was more inclined towards Kafka due to this reason. For me the only worry was how well it cops with rest of technology stack. Fortunately, it had good C# client libraries to work with.
- Redis Enterprise - This was again a more promising choice. It too had inherent capabilities of scale along message delivery capabilities. Since redis is our primary database, it made more sense to go for this but unfortunately their licensing strategy was not aligned with how our application was designed to operate. It was becoming insanely expensive making us to drop this out.
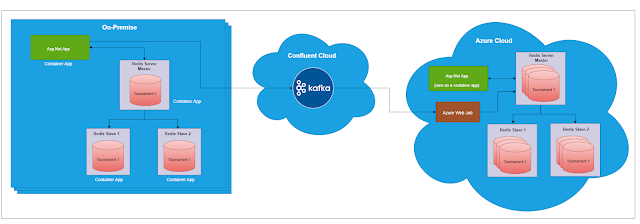
The overall message delivery was within a second for several concurrent matches. It was a good and satisfactory outcome.