- Should develop a sports management software which would work both offline and online. In other words, on-premise and cloud.
- The offline data should sync with cloud instantly or eventually depending on the internet availability at on-premise system.
- The software should be integrated with couple of external systems. Both to consume and send data.
- The live match data delivery latency should be less than a second.
- The on-premise software should be highly available so that the live match data entry is never interrupted (This is the primary reason why on-premise requirement came in the first place! because historically internet is not reliable at various stadiums).
- The on-premise software should have mechanism to integrate with display devices available at the stadium.
- The on-premise system should have the ability to send data to local consumers.
- The cloud version should be geographically distributed and can have data consumers all over the world.
If we draw a diagram for this requirement, it would look something like this
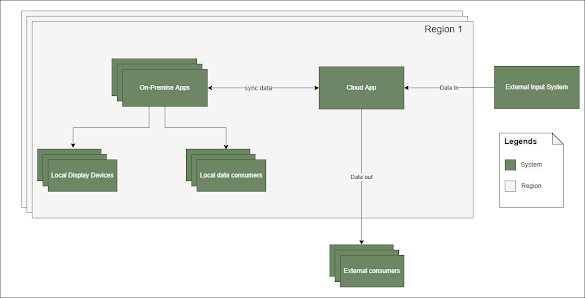
From the summary, its pretty evident that we need a distributed solution with the requirement favoring AP over C of the CAP theorem. That is Availability and Partition tolerance over Consistency (not to confuse with consistency guaranteed in ACID database transactions. Its the consistency of the distributed systems that we are talking about here. Specifically its the data synchronization of on-premise and cloud counterpart of the software here).
From the application functionality stand point both on-premise and cloud counterparts had almost same features except very few which was specific to either on-premise or cloud. So with that in mind we decided to go with same source code for both on-premise and cloud implementation.
After months of research, brainstorming and POCs measured across various metrics such as performance, maintainability, external integration aspects, cost, time to develop, skilled resource availability at hand etc., we finalized following tech stack for the implementation -
- Asp.net Core 3.1 with C# for backend development.
- Angular for front-end development.
- Redis as primary DB - Yes, you heard it right - Its not used for caching purpose here! but as a primary sports database with persistency enabled (will have an article dedicated for this topic later).
- SQL Azure for cloud - To store some metadata information.
- Azure Functions - For some server less computations.
- Azure Storage - To store images, videos and other binary data.
- Apache Kafka as a message broker between on-premise, cloud and external systems.
- Azure Web Jobs for some long running background work which was not suitable for Azure Functions.
- Signal-R - To push real-time data from server to angular front-end.
- Docker with Linux as a runtime environment.
I will discuss about the thought process behind these choices as we move on with each topic.
Data Structure and Manipulation
How we structure our data plays an important role in any system design. Hence our first focus was to formalize a structure which was easy to work with yet have all the necessary properties for syncing purpose.
Basically we created an object structure to represent a single transaction unit which is composed of header and body parts. The header section contained metadata of the transaction such as timestamp, transaction id, tournament id, etc., where as the body part is a collection of real data along with type of an operation(it can be either set or delete - this is the only 2 write operations possible with redis hash table and that's our primary database - the reason for choosing this will be covered in the upcoming articles).
In other words, one transaction unit in our application is fundamentally composed of multiple redis operations spanning across multiple hash tables.
We also made a decision that for one API call, we will have only one redis transaction commit. This guarantees that all the operations performed in a single web request is atomic in nature. Any failures in this will end up as an error to the invoker and retry can be performed.
To ensure above design is strictly followed by all application developers in the team, we enforced it with the combination of generic repository pattern without save/commit feature and decorator design pattern or more practically speaking Middleware feature of Asp.Net Core.
Here is the diagrammatic representation of the same -

The diagram is an oversimplified version of the real implementation. Showing only the components essential for this discussion.
This is a foundation stone of the overall solution.